SPATIAL ANALYSIS IN GIS
GIS is differentiated from other information systems due to its
spatial analysis functions.
Spatial analysis functions are used to answer questions about the real world using GIS databases as a model of the real world.
Spatial analysis techniques are used to create an image of reality that can be easily understood.
Basic spatial analysis can be performed at various levels:
- Sorting data in attribute tables for presentation
- Performing arithmetic, boolean and statistical operation on attribute tables
- Compiling new data based on original and derived attributes or based on geographic relationships.
- Within each level operations may be logical, arithmetic, geometric, statistical or a combination of any of these four types.
The two fundamental functions of GIS are:
- Generation of maps and
- Generation of tabular reports
Spatial analysis requires logical connections between attribute data and map features. Spatial analysis builds operational procedures on spatial relationship between map features.
Attribute query involves selecting information by the use of logical questions. When no spatial information is required to ask a question, the query is considered an attribute query.
A spatial query involves selecting features based on spatial relationships. The answer to such queries can be obtained by a hard-copy map or by using a GIS.
Basic GIS analysis involves attribute queries and spatial queries. Complicated analysis require a series of GIS operations involving multiple attribute and spatial queries, alteration of original data and generation of new data sets.
An effective spatial analysis uses the best available methods appropriately for different types of attribute queries, spatial queries and data alteration.
The design of the analysis depends on the purpose of the study.
The use of GIS to inquire geographic features and retrieve associated attribute information is called identification. This process generates new set of maps by query and analysis. Spatial analysis helps make the new information clearer. GIS operational procedure and analytical tasks that are suited for spatial analysis are discussed below:
- Single layer operations are procedures that correspond to queries and alterations of data that operate on a single data layer. For example, creating a buffer zone (silence zone) around all schools in a city is a single layer operation
- Multi layer operations are used for manipulation of spatial data on multiple data layers. For example, the overlay of two input data layers produces a map of combined polygons.
- Topological overlays: These are multi layer operations that allow combining features from different layers to form a new map and give new information and features that were not present in the individual maps.
- Point pattern analysis deals with examination and evaluation of spatial patterns and processes of point features.
- Network analysis: It is designed specifically for line features organized in connected features and typically applies to transportation problems and network analysis. For example: school bus routing, walking distance, bus stop optimization, etc
- Surface analysis deals with the spatial distribution of surface information in a three dimensional structure.
- Grid analysis involves processing of spatial data in a regularly spaced form.
- Fuzzy spatial analysis is based on fuzzy set theory. Fuzzy set theory is a generalization of boolean algebra where zones of gradual transition are used to divide classes instead of crisp boundaries. Fuzzy algebra offers various other methods to combine different sets of data for landslide zonation map preparation. Fuzzy logic can also be used to handle mapping errors or uncertainty.
Geostatistical tools for spatial analysis
Geostatistics studies the spatial variability of regionalized values. Tools to characterise spatial variability are:
- Spatial auto-correlation function and
- Variogram
Spatial auto-correlation examines the correlation of a random process with itself in space. Examples of such phenomena are:
-Total amount of rainfall
-Toxic element concentration
-Elevation at triangulated points, etc
The spatial auto-correlation function depicted as a graph is called a spatial auto-correlogram and this gives an insight into the spatial behaviour of the phenomena under study.
A variogram is calculated from the variance of pairs or points at different separation.
Spatial analysis is a vital part of GIS and can be used for many applications like:
- Site suitability
- Natural resource management
- Environmental Disaster Management
Spatial Analysis is the heart or core of GIS because it includes transformations, manipulations and methods that can be applied to geographic data to support decisions, reveal patterns and anomalies not immediately obvious and add value.
Spatial analysis is a set of methods whose results change when locations of the objects being analysed or the frame used to analyse them changes.
Spatial analysis can be:
- Inductive: Examining empirical evidence and searching for patterns that might support new theories or general principles
- Deductive: Focussing on testing of known theories against data
- Normative: Using spatial analysis to develop new or better designs
Analysis can also be carried out on attribute tables of a GIS by plotting one variable against the other as a scatterplot and examining the dependence of one variable on one or more independent variables
Regression analysis can be used to find the simplest relationship and multiple regression can be used to understand the effects of multiple independent variables.
Changing relationship between variables with space is called spatial heterogeneity.
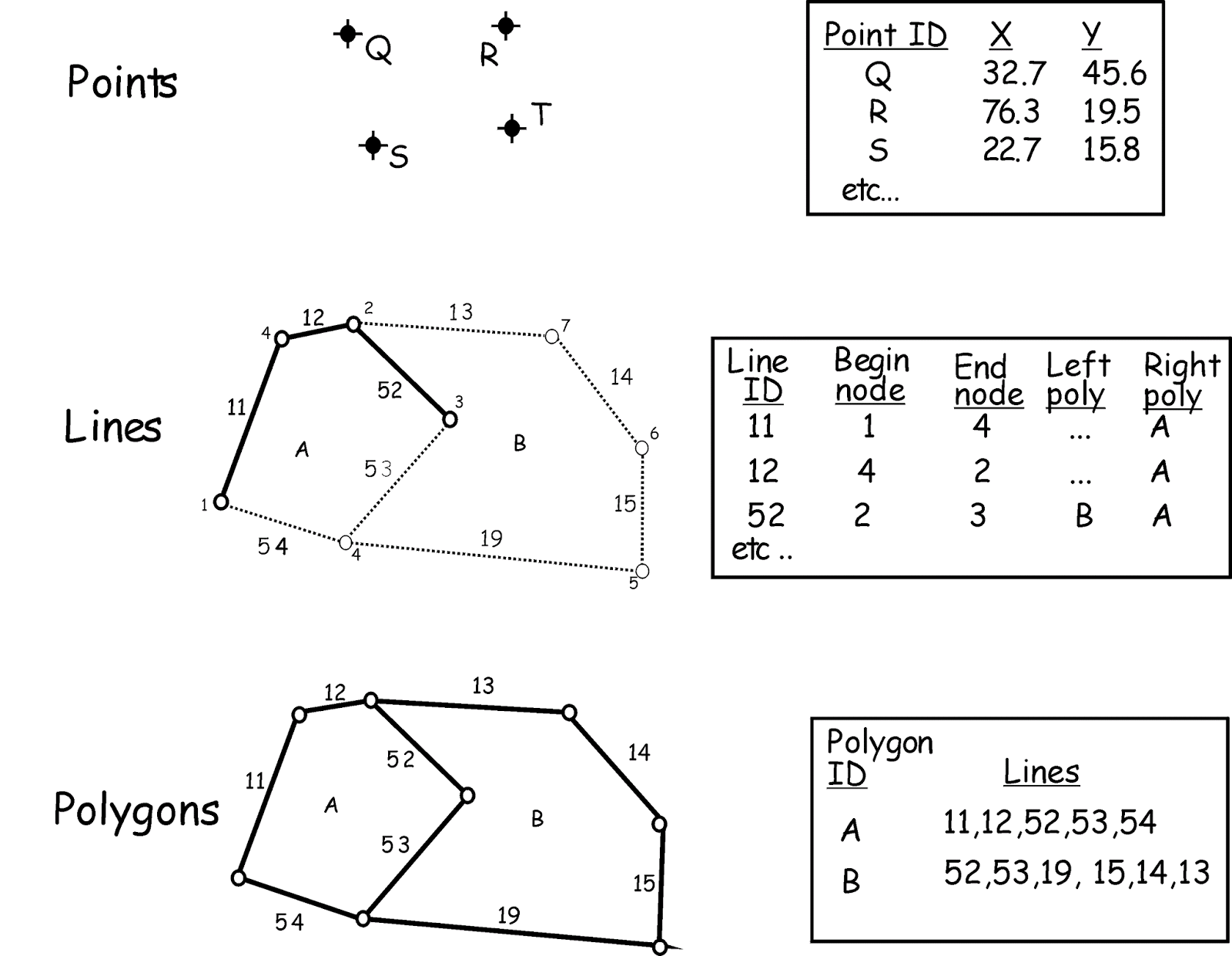
One of the most powerful features of a GIS is the ability to join tables based on common geographic location.
The point-in-polygon operation is used to determine if a point lies inside or outside a polygon.
The polygon overlay is similar to the point-in-polygon operation.
Overlay in raster is very simple. The attributes of each cell are combined according to a set of rules.
The ability to calculate and manipulate distances forms the basis of spatial analysis.
Distance along a route (represented by a poly-line) is calculated by adding the lengths of each segment of the poly-line.
Since poly-lines short-cut corners, the length of a poly-line is shorter than the length of the object it represents leading to slight discrepancy.
Buffering builds new objects by identifying all areas that are within certain specified distance of the original object.
Point patterns can be identified as clustered, dispersed or random.
There are SIX CATEGORIES of spatial analysis:
- Queries and reasoning
- Measurements
- Transformations
- Descriptive summaries
- Optimization and
- Hypothesis testing
Queries and reasoning are the most basic analysis operations where GIS is used to answer simple questions. No changes occur in the database and no new data are produced.
Measurements involve measurement of simple properties of objects such as length, area or shape and relationship between pair of objects such as distance or direction.
Transformations are simple methods of spatial analysis that change data-sets by combining them or comparing them to obtain new data-sets and finally new ideas. Transformations use simple arithmetic, geometric or logical rules. They include operations that convert raster data to vector data and vice versa. They may create fields from collections of objects or detect collection of objects in fields.
Descriptive summaries attempt to capture the essence of a data-set in one or two numbers.
Optimization techniques are normative in nature and are designed to select ideal locations for objects given specific constraints. They are widely used in market research, package delivery industry, etc.
Hypothesis testing focusses on reasoning from the results of a limited sample to make genaralizations about an entire population. Hypothesis testing is the basis for inferential statistics and forms the core of statistical analysis.
Spatial analysis can be done by overlay analysis by overlaying land use and flood zone to determine the residential parcels inside a flood zone area. This data can be used by insurance companies to target their insurance sales.
Farmers can use interpolation to examine soil samples from a farm area.
Shop owners can establish their stores based on location (distance and density) analysis
Data types in spatial analysis
The three types of data used to characterize problems of spatial analysis are:
- Events or point patterns: Examples of this type are: crime spots, disease occurrences, localization of vegetal species, etc.
- Continuous surfaces: Examples of this type are: geological maps, topographical maps, ecological maps, etc.
- Areas with counts: Examples of this type are: population surveys, health statistics, etc that are demarcated by closed polygons (postal zones, municipalities, etc)
Problems of spatial analysis deal with environmental and socioeconomic data.
Basic concepts of spatial analysis
- Spatial dependency is an important concept to understand and analyse a spatial phenomena. "Everything is related to everything else, but near things are more related than distant things" -Waldo Tobler (First law of Geography)
- The computational expression of the concept of spatial dependence is spatial autocorrelation.
- Statistical inference for spatial data: An important consequence of spatial dependence is that statistical inferences on this type of data will not be as efficient as in the case of independent samples of the same size.
Spatial interpolation is the process of manipulating spatial information to extract new information and meaning from original data. GIS provides spatial analysis tools for calculating feature statistics and carrying out geoprocessing activities as data interpolation.
The two widely used interpolation methods are:
- Inverse Distance Weighting (IDW) and
- Triangular Irregular Networks (TIN)
Other interpolation methods are:
- Regularized Splines with Tension (RST)
- Kriging or Trend Surface Interpolation